
言語や環境設定、スクレイピングの入門記事があります。
学習の準備やその他のプログラミングは次で説明しています。


AIの活用で解決
チャットAIを使いこなせば、精度の高い回答を得られるようになります
特にプログラミングでは強力なサポートツールになるので、今後は活用が必須になっていくはずです。
AIを使いこなすためにはプログラミングを概念的な理解しておくことが重要です。
概念的な理解とはコードではなく言葉で理解することです。
「Exception」などの単語やコードよりも、例外/エラー処理などの概念として理解すべきです。
そうすることで、単語のつづりを忘れても、あるいは他の言語でプログラミングする場合でも、似た処理を調べることができ、AIをより汎用的に活用することができるようになります。

もう自分で検索するよりAIに聞いた方が早い時代になったんだ。
シンギュラリティ(技術的特異点)って言うんだけど、馬車から自動車に変わったように、プログラミングもAIにサポートされながらする時代になったんだね。
開発環境
この記事は以下の環境で実行した結果に基づいたものです。
- Windows11
- Python 3.11.4
環境構築の基本
Pythonの文法を学ぶだけなら、オンラインサービスのGoogle Colaboratoryを使えば環境設定不要でPythonコードを実行できます。
初めてPythonやプログラミングを学ぶならこれでもいいでしょう。
もっと本格的に学んだり、外部ライブラリを使っていくときはAnacondaパッケージでPythonをインストールして使うのがおすすめです。
コンソールからPythonなど必要なものだけをインストールして使うこともできますが、最初はセットのパッケージをいれておいたほうがいいでしょう。
Anacondaパッケージに入っているJupyter Notebookも数行ずつ実行できるので初心者向きです。
ColaboratoryやJupyter Notebookは手軽に使えるので、経験者にとっても文法や短いコードを確認するのに便利です。
ある程度長いコードを実行するならVisual Studio Codeが向いています。
VS Codeと略され、対応するプログラム言語やツールが多く、業界的に最もシェアがあるIDE(統合開発環境)です。
他にはPyCharmやAtomも人気です。
うまくいかないときの対処法
結論としては、PCの再起動とインストールのやり直しがおすすめです。
初心者で問題の原因がよくわからないときは、ゼロからインストールしなおしたほうが早いです。
中級者以上の人でもライブラリの相性などがあるので、入れ直したほうが早いことが多いのではないでしょうか。
Pythonは本体のバージョンアップが頻繁に行われるので、ライブラリの更新が間に合わなかったり、そもそも停止されていたりすることがあります。
そこまで調べる時間を考えると、とりあえず再インストールを試すくらいでいいのかもしれません。
Pythonはそれくらい安定性がないです。
エラーメッセージを信じて何時間も対処したけど、原因が特定できず、うまく動かないことがあった。
エラーの解釈や対応が悪かったのか、ライブラリの相性が悪かったのかは特定できなかったけど、入れ直したら動いたのでよしとした。
Python の本体 Anaconda Package のインストール
公式サイトで各OS向けのインストール方法が説明されています。特に難しくはないので書いてある通りにやればインストールできるはずです。
参考 [公式]Python環境構築ガイド – python.jp
URL:https://www.python.jp/install/install.html
簡単に説明しておくと次のような手順になります。
0.基本 バージョン問題は難しい
Python やライブラリ、アプリなどのバージョンが合わないと正常に動作しません。
インストール前に互換性のあるバージョンかどうか確認しましょう。インストール関連では、できれば1年以内などの新しい記事を参考にしたほうがいいです。
インストール/アンインストール/アップデートなどはアプリやサーバーを終了させてから行います。
起動中にアップデートしたり、オートアップデートが開始された場合は終了させないと、アップデートでエラーが起こったり完了しないことがあります。
またその他の設定も再起動しないと反映されないことがあるので、設定などを変更した後にうまく動作しないときは再起動したほうがいいです。
コーディングでもバージョンによってPythonの文法が異なりエラーになったりするので、環境設定後は下手にアップデートなどはしないほうがいいです。
ネット記事や本、学習教材などもバージョンが違うとエラーになる可能性があるので、文法だけでなくバージョンに原因がある可能性があることも覚えておいてください。
1.古いバージョンのアンインストール
過去に Python をインストールしたことがある人は古いバージョンを削除しておいてください。複数のバージョンが混在すると正しく動作しない恐れがあるからです。
古いバージョンで開発したものを動く状態にしておきたい場合は削除せずにそのまま使ってもいいです。
本や教材などでバージョンが指定されている場合も、そちらの内容が終わるまで変更しなくていいでしょう。
2.パッケージのインストール
Pythonのディストリビューションである Anaconda Installer でダウンロードしてインストールします。これでPythonのcondaパッケージがインストールされます。
3.初期設定
インストールされた Anaconda Prompt から Python を起動して初期化します。Anaconda Prompt で[conda init]と打ってエンターを押せば完了です。
注意:権限エラーになるので Anaconda Prompt は管理者権限で起動すること
4.PowerShell の設定
Anaconda Prompt でも操作できますが、Windows の PowerShell というコンソールからも操作できます。
公式サイトに PowerShell から Anaconda を使うとエラーになることがあるとあります。対処法が載っているのでエラーが出た人は対処しておきましょう。
私が PowerShell 起動したら最新版を使うようメッセージが出たので、同じ人は念のため最新版にしておくといいです。
winget install --id Microsoft.Powershell途中で確認が入ったときは「y(はい)」を入力して進めてください。
次のGitHubのページで「Get PowerShell」の項目からダウンロードできるので、使うOSのLTS版を使うのが無難です。
5.コンソールからの動作テスト
コンソール(コマンドプロンプトやPowerShellなど)でpythonと入力してPythonが起動すればインストール成功です。
Windowsではpyで最新バージョンが実行されます。
インストールの参考ページにも書いてありますが、”1+1″と入力して2が表示されたら正しく動作していると判断できます。
6.Jupyter Notebook の起動テスト
Python は Anaconda Prompt などのコンソールからでも起動できますが、せっかく Anaconda Navigator という GUI があるので Jupyter Notebook で実行できるようにしてみてください。
デフォルトブラウザで Jupyter の画面が表示されればパッケージのインストールまでは完了です。Anaconda Navigator はパワフルなツールですが起動に時間がかかります。
Jupyter の Lab と Notebook どちらがよいか?
Anaconda Navigator には Jupyter の Lab と Notebook の2つの Jupyter が表示されます。初心者にとってはどちらも似たようなものなので好みで選べばいいでしょう。
開発用に長期的に使うなら、Notebookの後継で拡張性の高いLabのほうがおすすめです。Labのほうが複数のノートブックうを扱える点でも優れています。
将来的にNotebookをLabに置き換えることが予定されている点からもLabのほうがおすすめです。
Jupyter Notebook
コンソールから起動
Anaconda Prompt から「jupyter notebook」と入力すると起動できます。
次の項目で説明している Anaconda Navigator なら GUI なのでマウスで操作できます。ですが、起動が遅いので、コンソールから起動したほうが早いです。
また Anadonda Navigator で他のアプリを起動しないなら Anadonda Navigator は必要ありません。起動しないほうがメモリを節約できます。
どちらから起動しても同じものが起動します。
Anaconda Navigator から起動
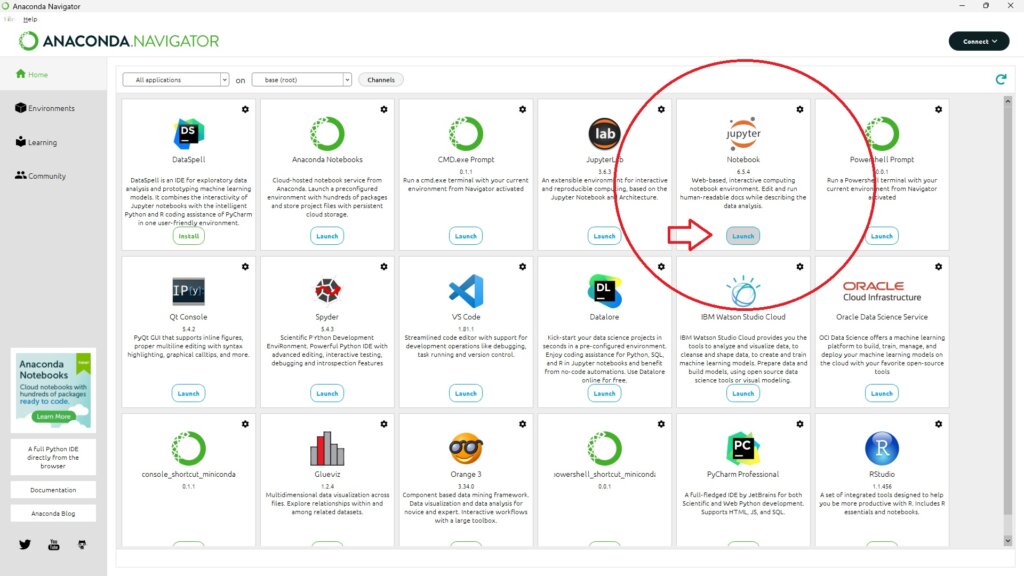
Jupyter Notebook はどこにあるか分かりにくいので下の画像を参考にしてください。「Launch」ボタンから起動できます。
ローカルマシン上でサーバーを起動するので少し時間がかかります。
Jupyter Notebook など使うアプリが決まっているなら、わざわざ Navigator を起動せずに、コンソールから直接起動したほうが早いです。
さらに、Navigator という不要なアプリを起動せずにすむのでPCのリソースも節約できます。
エンジニアたるもの時短・節約思考が大事なので最短コースを選ぶよう心掛けたほうがいいです。
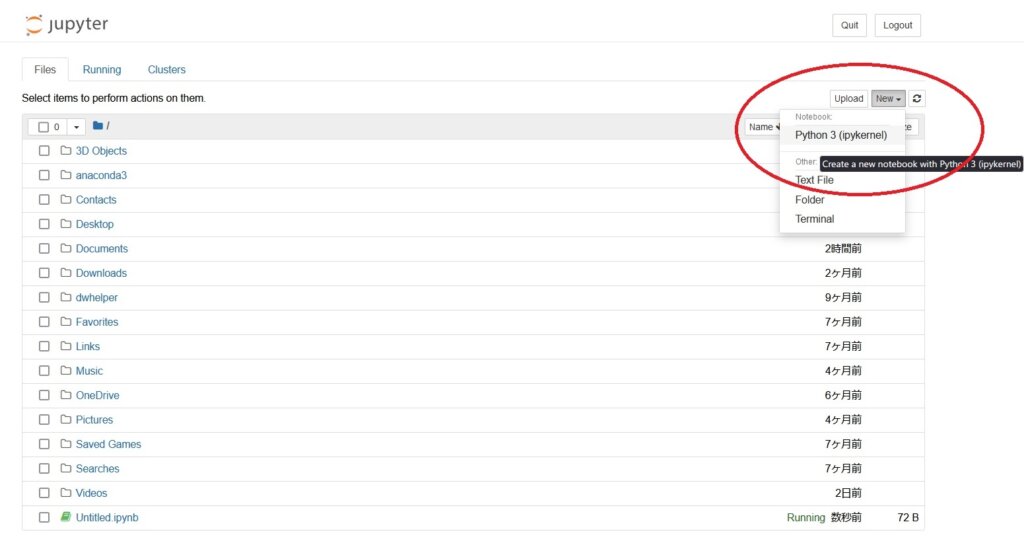
Jupyter Notebook が起動したら、最初の「File」タブで右上の方の 「New」 > 「Python3」 から新しいノートを作ると Python コードを実行できるようになります。
- 実行
ブロックで実行ボタンか Shift+Enter で各ブロックの処理が実行されます。
- 終了
Fileメニュー:Close and Halt(サーバーが本体なのでウィンドウの×ボタンでは終了しない)
以下はコマンドモードでの操作(コマンドモード:Esc押下)
- セル削除:d 2回
- コード/マークダウン切り替え:y or m
Jupyterは再起動でキャッシュが消える
Jupyter(Lab/Notebook)でコードを実行するとブロックごとに左に番号が表示されます。これは実行した順番を表しています。
先に実行した処理の結果はキャッシュされることで、別の処理で利用できるようになります。
そのため、Jupyterを再起動した直後はキャッシュがなくなっているので、途中の処理から始めようとしても意図した結果にならないことがあります。
これを回避するには、処理の順番通りに上からなど必要なブロックをすべて実行していく必要があります。
「再起動したら、処理をやり直す」と覚えておいてください。
Visual Stuidio Code
これは Python 開発でも人気のる統合開発ツールです。VS Code と略され、多言語対応でプログラミング業界の標準ツールになっています。
VS Code と Anaconda Package を連携させます。別の項目で説明しているので、こちらもインストールしておいてください。
VS Code のインストール
次のサイトからダウンロードしてインストールします。インストール時の設定は、後から変えられるので、デフォルトで問題ありません。
参考:Visual Studio Code – コード エディター Microsoft Azure
URL:https://azure.microsoft.com/ja-jp/products/visual-studio-code/
Python拡張機能をインストール
VSCodeを起動し、左サイドバーから拡張機能を選び、「Python」と入力すると一番上に出てくる「Python extension for Visual Studio Code」をインストールします。
VS Code でワークスペースを作る
ワークスペースの概念は初心者泣かせの難しさなので別の記事で説明しています。
実行テスト
ワークスペースに拡張子pyのPythonファイル(例:test.py)を作って「print(‘Hello World ‘)」と書いて実行してください。
VS Code でファイルを実行するには PowerShell などから、「python test.py」と入力し実行します。
あるいは、Shift+Enter でも Python コンソールでその行を実行することができます。
F5キーを押して、コマンドパレットの選択候補から Python ファイルを実行を選択することでも実行できます。
コンソールに「Hello World」と出力されたのが確認できたら、環境構築はひとまず完了です。
PowerShell の conda コマンドエラー対策
Windowsだとパスが通っていないなどの理由でエラーになることがあります。
私の環境もWidnows11だったのでエラーになりました。チャットAIに質問したら初期化しろということだったので初期化したら解決できました。
Anaconda Prompt で「conda init powershell」と入力し実行。
近頃はパスを設定したファイルを書き換えなくても良くなりつつあるようです。
私はこれで解決してしまったので、他の解決法は試していませんが、気になる方はAIに聞いてください。
これはもうsinngyurarhiだね。自分で調べるよりAIに聞いた方が早い時代になっちゃったね。
もう、そういう時代だから、まずはAIに聞くといい。
AIもネット記事を検索してるだけだったりするから、まぁ、自分で検索するのと似たようなことじゃないかな。
公式サイトを参考にする
この記事や他の日本語記事の説明でうまくいかないときは、英語ですが公式の説明があるので参考にしてください。
参考:[VS Codeの公式] Using Python Environments in Visual Studio Code
URL:https://code.visualstudio.com/docs/python/environments
参考:[Anacondaの公式] Python for Visual Studio Code — Anaconda documentation
URL:https://docs.anaconda.com/free/anaconda/ide-tutorials/python-vsc/
バージョン管理/変更
最新のPythonにバージョンアップすると、ライブラリが対応していないせいでエラーになることが多いです。
ライブラリによってサポートされるPythonのバージョンが違うので、先にサポート状況を確認してからバージョンアップすべきです。
Pythonのアプリやサービスを長期運用するときは特に注意が必要です。
インストール済のPythonのバージョンはpyenvというライブラリで変更できます。
新バージョンでの動作テストをするときや、ダウングレードするときに使います。
バージョン変更がうまくいかない場合
Python関連のものをすべて削除して、ゼロからインストールし直すのが確実な復旧方法です。
異常が出ている部分を探すのは大変なのでおすすめではありません。
環境構築は問題を探すのが難しいことがあるので、初めからDockerなどの仮想環境で構築するほうが安全です。
- プログラムの追加と削除などからPython関連(Anacondaなど)をアンインストール
- C:\Users\(ユーザー名)\AppData\Local\Programs\Python配下の不要フォルダ/ファイルを削除
- C:¥Users¥(ユーザー名)¥AppData¥Local¥pipフォルダがあれば削除
- 環境変数のPathにPython関連のパスを設定してあれば削除
※Python関連ではPCの再起動は特に必要ありません。メッセージで要求されたときだけ再起動すればいいでしょう。
pyenvの使い方
Python のライブラリなので pip でインストールしておくのがおすすめです。
VSCodeのPowerShell(PWSH)で実行しておけばいいでしょう。
- インストール
PowerShell/Git Bush:pip install pyenv-win –target $HOME\.pyenv
コマンドプロンプト:pip install pyenv-win –target %USERPROFILE%.pyenv - エイリアスの変更
Win11:スタート > 設定 > アプリ > アプリの詳細設定 > アプリの実行エイリアス
アプリインストーラーのpython.exe/python3.exeをオフにする - PYENV と PYENV_HOME を環境変数に追加
ターミナルから次の2つのコマンドを実行
[System.Environment]::SetEnvironmentVariable(‘PYENV’,$env:USERPROFILE + “\.pyenv\pyenv-win\”,”User”)
[System.Environment]::SetEnvironmentVariable(‘PYENV_HOME’,$env:USERPROFILE + “\.pyenv\pyenv-win\”,”User”) - pyenvコマンドの設定
次のコマンド(1行)を実行
[System.Environment]::SetEnvironmentVariable(‘path’, $env:USERPROFILE + “\.pyenv\pyenv-win\bin;” + $env:USERPROFILE + “\.pyenv\pyenv-win\shims;” + [System.Environment]::GetEnvironmentVariable(‘path’, “User”),”User”) - インストールの成否確認
次のコマンドでバージョンその他の情報が表示されれば成功
pyenv –version
環境変数はGUIから編集することができます。(スタートボタン > 設定 > バージョン情報 > (関連リンク)システムの詳細設定 > 環境変数)
使うときもターミナルから操作します。
- 念のため最新化(インストール済の場合)
pyenv update - 使用可能なバージョンの確認
pyenv install –list - pyenvにPythonを登録
pyenv install 3.9.3(例) - 導入済のPythonバージョンの確認
pyenv versions - 使うバージョンを設定(global)
pyenv global 3.9.3(例) - 使うバージョンを設定(local)
pyenv local 3.9.3(例)
参考:【Python】pyenvの使い方(備忘録)|星杜なぎさ
URL:https://note.com/nagisa_hoshimori/n/n061d4cded427
Python入門メモ
Google Colaboratory(Colab) なら環境設定いらず
プログラミング初心者に立ちはだかる最初の壁が環境設定です。
環境設定とは、具体的には必要なツールやエディターなどをインストールしたり、ライブラリのパスを設定したりする作業のことです。
経験者でも面倒なことなので単にプログラミングを学びたいだけなら環境設定がいらないオンラインサービスを使った方が楽です。
環境設定不要、オンラインでPythonコードが実行できるのが Google Colaboratory です。(※利用にはGoogleアカウントが必要)
- Google Colaboratory から ファイル > ノートブックを新規作成で実行プロジェクトを作成
- 右上の接続アイコンから接続
- 再生アイコン(三角形)の右にコード書く
- 再生アイコンを押すとコードが実行される
左上の「+コード」ボタンを押すとセルが作られコード記述と実行ができます。コードを書くときはこのボタンを使います。
「+テキスト」ボタンを押すとテキストが入力できるようになります。テキストを書いたあとに Shift+Enter を押すとテキストが出力されます。
これはコード以外のメモを残す機能で、これでソースコード内にコメントを残すことができます。
また Shift+Enter は再生アイコンを押したときと同じ動作をするショートカットキーでもあるのでコードもこれで実行すると便利です。
Colaboratory の機能で単に変数だけを書いて実行するだけで中身を表示することができます。
ですが、これはPythonの仕様ではないので通常の環境では出来ないので注意してください。
Colaboratory(Colab)からGoogleドライブにファイル出力
設定するとPythonでスクレイピングしたデータをCSVファイルとして出力したりできます。
- ブラウザからGoogleにログイン:「…」メニュからGoogleドライブへ
- 左上「新規」⇒「その他」⇒「アプリ追加」を選択
- 「Colaboratory」と検索してインストール
Colaboratoryの起動はURLかGoogleドライブからできます。
- Googleドライブをブラウザで開く
- 「新規」⇒「その他」⇒アプリの「Google Colaboratory」を選択
ちなみに、私は覚えがないのですが、インストールされていました。
元からソースファイルをGoogleドライブに保存する仕様なので、Colaboratoryに一度ログインしてあれば設定は必要ないようです。
Pythonの環境構築方法
プログラミングだけならオンラインサービスでも学べますが、実行ファイルなどの本体を作れる無料サービスはまだ存在しないようです。
せっかくPythonを学ぶなら、実際に動くプログラミングを作って、スクレイピングで日々の作業を自動化するくらいのスキルは身に着けたいものです。
そんな目的があるならやはり自分のPCにインストールして環境構築しないといけません。
次が簡単なやり方です。
Pythonの環境構築から起動まで
- ダウンロード&インストール
英語の公式サイトから Anaconda Installers をダウンロードしてインストール
※注意1:筆者のノートPCに入れたら30分くらいかかった
※注意2:パス(フォルダ名)に日本語や半角スペースが入らないようにする - プログラムメニューの「Anaconda Prompt」から起動(Windowsの場合)
- プロンプトから「python」と入力すればPythonが起動
- 「exit()」で Python 終了、プロンプトは「exit」で終了
細かい部分はPythonの公式ページに日本語で説明されているので詳しくはそちらをご覧ください。
参考 [公式] Python環境構築ガイド – python.jp
URL:https://www.python.jp/install/install.html
基礎文法
ここでは概要をつかむための基本を説明します。詳細はネット記事や公式ドキュメントを参照してください。
Pythonではカッコの形の違いで処理を分けたり、省略可能なパターンが多い特徴があります。どちらも見落とさないように注目してください。
より少ないコードで記述することはPythonの言語テーマでもあります。省略や簡略化できる記述は積極的に使っていきましょう。
基本的な説明は次のサイトが分かりやすいのでおすすめです。
参考 Python早見表
URL:https://chokkan.github.io/python/index.html
また、Pythonのバージョン2から3のメジャーバージョンアップで多くの変更がありました。
小数点以下で表すマイナーバージョンアップでもバグフィックスだけでなく、新しいメソッドや記述が追加されるなどの変更があります。
どのバージョンを使っているかは常に意識しておく必要があります。
正しい文法が説明されているのは公式ドキュメントなので、詳細は公式でバージョンごとの仕様を確認してください。(※まれに間違っていることもあるので注意)
参考 [公式] Python 標準ライブラリv3.10.12
URL:https://docs.python.org/ja/3.10/library/index.html
・変数の確認
変数名だけ書いて実行するとコンソールに内容が表示されるので確認できます。文字列を追加したいときなどは print(‘a=’, a)などとすると”a=数値”のように表示されることもできます。
・コードのエラー
「SyntaxError: invalid syntax」などのように表示されるのがエラーメッセージ。
英語でエラーの種類や内容が表示されるので、勘で対処せずに、最初に起きたエラーから自動翻訳を使うなどして意味を理解して対処する。
よくあるエラーは、変数名、関数/メソッド名、カッコ、記号、インデント(行頭の空文字)、型などの間違い。
・1処理ごとに改行が必要
改行が処理の終わりの制御文字になっているので、初期化や関数、メソッドなどの処理を1行にまとめて書くことはできない。
1処理ごとに改行しないとエラーになる。
・print関数
文字列/数字/変数を標準出力(sys.stdout)に表示する関数。(sysは標準ライブラリのモジュール)
・文字列
シングルクォート(‘)かダブルクォート(“)で囲む。
・シングルクォート/ダブルクォートによる文字列のエスケープ
シングルクォートやダブルクォートを文字列内で使うときはバックスラッシュを付けてるとエスケープすることができる。
・文字列の連結
文字列は+で連結したり、*で乗算して追加することができる。
・文字列変数は配列データとしてインデックスでアクセスできる
文字列を入れた変数は配列データになっているのでstr[0]などで1番目の文字列データにアクセスできる。
・配列データのインデックス
インデックスの開始/終了/ステップ数を指定できる(スライスという機能):str[2:4]で2~4番目を表す。str[2:4:2]で2と4番目を表す。
最大値/最小値は省略可:str[:3]で1~3、str[2:]で2~最後までを表す。
マイナスで末尾からのインデックスを指定できる:str[-1]で末尾をstr[-2]で末尾のひとつ前を表す。
インデックスを省略すると全データが対象となる。
・シーケンス
順序のある要素を持ったデータのまとまりをシーケンスという。上の配列データのことインデックスの指定やスライスなどができる。
・unpack(アンパック)
リストなどからスライスなどして複数の変数に1文で代入できる省略表記。
v1, v2, v3 = l[0, 2, 4] でリストlの0,2,4番目の内容がそれぞれv1,v2,v3に代入される。
・配列データの追加削除
宣言後(初回代入後)に要素数を追加/削除できる関数がある。
要素の追加:list.append(idx)
配列の追加:list.extend(listB)、list+=listB、末尾から追加される
要素の削除:list.remove(num or var)、インデックスではなく合致する数値や文字列の最初の1つを削除
要素を取り出す:list.pop(idx)、要素の内容を取り出して要素を削除、idx省略で末尾のidxが対象になる
・コメントアウト制御文字はシャープ(#)
行末までコメントアウトされる(処理が無効になる)。
・比較演算子
if文やfor文なので比較で使う演算子。
A==B:AとBは同じ
A!=B:AとBは違う
A<B:AはBより小さい(Bを含まない)、 >は逆
A<=B:AはB以下(Bを含む), >=は逆
A is B:AとBは同じオブジェクト
A is not B:AとBは違うオブジェクト
・関数とメソッドの違い
単体で呼び出せるのが関数、’.'(ドット)でつなげて呼び出す処理がメソッド。
メソッドはクラスやデータ型で定義されオブジェクトやモジュールから呼び出す。
・セイウチ演算子(:=)
代入と使用(比較など)が同時に行える演算子、Pyhotn3.8以降で使えるようになった
・内包表記
for文でリストや辞書を簡潔に生成するための構文。条件分岐(if文)やネストもできる。Pythonの独自仕様。分かりにくいので初心者が無理に使う必要はない。
・その他の仕様
文法や仕様の詳細はバージョン別の公式ドキュメントがあるので参考にしてください。
参考 [公式] Python 標準ライブラリ v3.10.12
URL:https://docs.python.org/ja/3.10/library/index.html
Pythonは動的型付け言語
変数を扱うときに型を宣言しなくても使える言語を動的型付け言語といいます。コードが短くなるメリットがあります。
デメリットは、型が違うというエラーが出たときに、どの型を使うべきかわかりにくいことです。(エラーはTypeErrorとなり要求される型が知らされないため)
初学者の場合は、コード補完や言語仕様を調べてもよくわからないでしょうから、チャットAIに類似のサンプルコードを出力させるのがおすすめです。
型宣言を省力できるからといっても、型自体は自分で理解して管理しないとコーディングできません。自分が扱っている変数が何型なのかは常に意識しておくようにしましょう。
静的型付け言語
動的型付け言語に対する概念が従来の静的型付け言語です。静的型付け言語では、あらかじめ変数と型を宣言しておかないと、変数を扱うことができませでした。
動的型付け言語はモダンな言語で導入されている比較的新しい概念です。
近頃は動的型付け言語がデバッグしにくいという弱点から、静的型付け言語が再評価されつつあります。
Pythonみたいな省略が命みたいな言語だと、型が把握しにくいから、静的型付け言語にしてほしかったな。
そんなに手間がかかる訳でもないのにね。
データ型
数値や文字列などのデータを入れる変数の型をデータ型といいます。扱うデータに適した型を選んで使います。
データ型は基本的にオブジェクトとして存在し、基本機能を提供するメソッドを持っています。
・データ型は最初の代入時に決まる
プログラム言語的には実質的な型宣言となる。初期化とも呼ぶ。
データ型は明示的に宣言しないが、整数を代入すれば整数型、文字列なら文字列型になる。
リスト型:l=[]
辞書型:d={}
・str/文字列
初期化法:” (ダブルクォート)か ‘(シングルクォート)で囲った文字列
数値型:int=整数、float=浮動小数点数、comlpex=複素数
・int/整数
初期化法:小数点を含まない数値
・float/浮動小数点
初期化法:小数点を含む数値
・bool/ブール
初期化法:True、False
・None
初期化して使うものではない、不在や欠如を表す特殊な数値、初期値や関数の戻り値などに使う
・datetime/日付
初期化法:関数での定義例 datetime.datetime(2020, 1, 31, 12, 36, 45)
・list/配列
初期化法:文字列、整数、論理値(true/false)など複数の要素、(list=[]で空の配列が宣言できる)
・tuple/タプル
初期化法は配列を同じ(t=()で空のタプルが宣言できる、※変更不能な(イミュータブルな)データ(オブジェクト)を定義できる)
・dictionary/辞書
初期化法:d={‘key1’:value1, ‘key2’:value1, …}
複数の要素と数値をセットのデータを作成できる
初期化時に各変数に代入する方法:key, value = {‘strKey’,5} これでそれぞれに文字列と数値が代入される。
キーを元にデータを参照できる、例:d={‘Key1’:1, ‘Key2’:2}(改行) print(d[‘Key1’])(実行)⇒出力:1
存在しないキーを指定するとエラーになるが、getメソッドを使うとNoneを返しエラーにならない、存在しないときに追加するなどのロジックが組める。
新しいキーを指定して代入することで辞書要素を追加できる、例:d[‘NewKey’] = 3(改行) print(d[‘NewKey’])(実行)⇒出力:3
辞書型データはitemメソッドでKeyとValueをセットで参照することができる。
・set/集合
初期化法:重複する値を無視した昇順のデータ(初期化時などにそのように整理される)。
集合同士の論理演算が可能(和/差/積など)。以降にある『集合の論理演算』を参照。
配列同士の論理演算や重複する値の削除、ソートに使える。list関数やset関数などで型変換することで必要に応じて使う。
・コンテナ型
複数の要素をまとめて扱うことが出来るデータ型のこと。リスト、タプル、辞書、集合などがコンテナ型にあたる。
構文
・if文
if 条件文 :(改行) elif 条件文: (改行) else: とつなげる、条件文の追加は and, or を使う。
・:(コロン)
if文やfor文の後に付けてコードのブロックを明示化する意味がある。
・イテラブルオブジェクト
繰り返し処理ができる性質を持つオブジェクト、具体的にはリスト、文字列、タプル、辞書、セット(集合)など。
・インデントでブロックを表す
インデント(字下げ、行頭の空白、スペース4文字推奨)でブロックを表す(カッコは使わない)。
・for文
[for 変数 in イテラブルオブジェクト :], 他言語のforeach文と基本は同じ。
break, continueも使える。
elseで終了処理を記述可能でbreakすると実行されない。
イテラブルオブジェクトではカウンターやインデックスなど様々な処理を指定できる。
ループ回数を指定するときは定数が指定できないのでrange(num)で指定する。
※C/Javaなどのようにカウンター変数で開始/終了インデックスなど指定することはできない。
次の例のように他にもいろいろな動きをする。
# リストのインデックスを指定しなくても要素の数だけ次のインデックスを参照し代入する
l = [1, 2, 3]
for num in l:
print(num)--- output ---
1
2
3イテラブルオブジェクトの例。
# enumerate はインデックスと要素を同時に取得できる
l_v = ['one', 'two', 'three']
data = {}
for i, v in enumerate(l_v):
key = i+1
value = v
data[key] = value
print(data)--- output ---
{1: 'one', 2: 'two', 3: 'three'}・while文
while 条件文:(改行) 処理 で条件が真のとき処理を繰り返す。
・match文
match 変数/リスト/辞書:(改行) case 1: 処理(改行) case 2:(改行) 処理 などとして使う、C/Javaなどのswitch文に近い構文。
組み込み関数
言語の仕様としてすでに実装されている関数を組み込み関数と呼びます。コードを書かなくても使えるデフォルトの関数のことです。
詳しくは次の公式ドキュメントを参照。
参考 組み込み関数 — Python 3.11.5 ドキュメント
URL:https://docs.python.org/ja/3/library/functions.html
・help関数
オブジェクトの持つメソッドなどを確認することができる。
l = []
print( help( l ) )
# 以下は出力される説明内容
Help on list object:
class list(object)
| list(iterable=(), /)
|
| Built-in mutable sequence.
|
| If no argument is given, the constructor creates a new empty list.
| The argument must be an iterable if specified.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
(以下、省略)最初は理解できないでしょうが、この例では、「これはリストオブジェクトのヘルプです。ミュータブル(変更可能)なシーケンス(要素がまとまったデータ)、かつ、引数はイテラブルオブジェクト(繰り返し処理ができるクラスの実体)である必要があり、引数なしで作成すると、空のリストができます。」などのことが説明されています。
・print関数
変数の内容をシステムコンソールに表示する関数。関数の引数にシングルクォートなしで数字を渡してもそのまま出力される。
学習/開発中は変数の内容が意図したものか確認するために頻繁に使うべき。
・type関数
変数のデータ型を調べる関数。
・型変換関数
int(var)などの形で任意の型に変換できる関数。
int/str/flat/list/dict/setなど様々な型の変換関数がある。
・range関数
範囲や条件を指定したデータ作成やforループの条件などに使う関数。
・enumrate関数
リストなどのインデックスと要素を同時に取り出せる関数。
・enumrate関数
for文でインデックスを取得したり要素を指定できる。例:for i, str in enumrate(listStr):
・len関数
文字列の長さを調べる関数。
・min/max関数
配列データなどの最大/最小を調べる関数。
ユーザー定義関数の作成
「def + 関数名():」と書いた後に処理を書くと関数が作れます。カッコの中に変数を書くことで引数も渡せます。また結果などを返すこともできます。
使うときは組み込み関数と同じく関数名()で呼び出します。
def は define の略で定義という意味です。定義は実装を決めているだけなので、定義しただけで使わなければ何も起きません。
・位置引数とキーワード引数
位置引数:書いた順番に渡される引数
キーワード引数:『引数名=値』と書くことで、書く順番に関わりなくその名前の引数に値を渡せる
位置引数とキーワード引数は同時に使うことができる(引数の数が違ったり、重複するとエラーになる)
・lambda(ラムダ)関数/無名関数
『lambda関数名 = lambda 引数1, 引数2… : 処理』と記述することで、lambda関数名(引数)と書いて処理を実行できる関数。
コードを簡略化できるため、簡単な処理の関数を使うときに使われる。
集合の論理演算
set型で使える論理演算を説明します。二つの集合に論理演算することでいろいろな条件の要素を取り出すことが出来ます。
- 集合和(+):すべての要素
- 集合差(-):差分(片方にだけある要素)
- 積集合(*):共通の要素
- 排他的論理和(^):片方にしかない(共通でない)要素
演算子の優先順
数学の掛け算や足し算がひとつの式で使われたときに、カッコがない場合には先に掛け算を計算するのと同じように、プログラミング言語の演算子でも優先順が決まっています。
デフォルトの優先順とは違う順番に評価したり、関係性を明示するにはカッコ'()’を使います。
参考 Python 演算子の優先順位
URL:https://www.javadrive.jp/python/num/index3.html
MacとWinのパス表記の違い
OSによってローカルフォルダの区切り文字が違います。Macがスラッシュ(/)でWindowsがバックスラッシュ(日本語Windowsでは円マーク[\])です。
Mac/Win兼用のコードを書くなら、違いに対応してくれるpathlibモジュールを使うと便利です。
文字化け対策
文字列やファイルのエンコードを指定して対処します。ネットで一般的なutf-8系にしておけばおおむね対処できます。
テキストファイルなどファイル自体にエンコードが指定できるファイルはutf-8を指定しておきましょう。
例外処理
起こりうる例外的な状況を想定した処理が例外処理です。例外処理を記述することで意図した正常な処理が行えない状況に対処します。
例外が起こりうる処理は try ブロックに書き、例外処理は except ブロックに書きます。try を使うといは except が必須になります。
else ブロックは例外起きなかったときだけ実行され、finally ブロックは例外の有無に関わらず必ず実行されます。どちらのブロックも省略可能です。
try:(必須)
# 例外が起こりうる処理(型の不一致など)
except:(必須)
# 例外が起きたときに実行される処理(例外への対処など)
else:(省略可)
# 例外が発生しなかったときに実行される処理
finally:(省略可)
# 例外の有無の関わらず実行される処理ログメッセージなどは、例外発生時は except に、正常時は else に、単にその部分が実行された記録は finnally にそれぞれ記述します。
例外対策は、そもそも例外は起こらないように先に型チェックなどを行うか、何も対処せずにログに関数名や理由を出力して、処理を終了することが多いです。
起こりうる例外が先に分かっている場合は、その例外用の処理を記述することもできます。以下は型の不一致に対する場合です。
try:
#関数内で型の不一致が起こる処理
a = func( 1 + '2' )
except TyepError as e:
# e が持つタイプエラーの内容を出力
print( e )
except as e:
# e が持つその他のエラー内容を出力
print( e )タイプエラー以外の例外が発生する可能性もあります。その他の例外にも対処できるように except も記述しておくべきです。
クラスとオブジェクト
クラスは設計図のようなもので、クラスを元に作られた実体がオブジェクトです。クラスは作ることができます。書く処理はメソッドと呼ばれ、関数のような形で定義します。
リストなどの組み込み型もクラスととして定義されています。
クラスからオブジェクトを作ることをインスタンス化と呼びます。オブジェクトはインスタンスとも呼びます。
一般的なクラスの定義方法は次です。
class ClassName( object ): # クラス名の定義
def __init__( self ): # オブジェクト作成後、最初に実行される初期化メソッド
self.x = 0 # メンバ変数の定義と初期化
self.y = 0
def setData( self, x, y ): # メンバ変数をセットする setDate というメソッドを定義
self.x = x
self.y = yクラス名は最初を大文字にすることが通例で、引数名は object とするルールです。
クラスをインスタンス化しオブジェクトを作ると最初に呼ばれるのが __init__ メソッドです。
「__init__」と名付けると初期化を行うためのメソッドとしてPythonに認識されます。初期状態にすることを初期化と呼び、最初に必要な処理を記述します。
メソッドの第一引数は必ずオブジェクトになります。self と命名するのが通例です。
またクラス内の関数にあたるメソッドで使う変数は __init__ で定義して初期化しておくのが一般的です。
setData などのメソッド名は自由に付けられます。
クラスの継承
オブジェクト指向言語では別のクラスの変数やメソッドを引き継ぐ継承という仕組みがあります。
Pythonでも継承が可能で、複数のクラスを継承する多重継承もできます。また親クラスのメソッドを書き換える場合に親クラスのメソッドを呼び出せるsuper関数もあります。
ライブラリ
共通機能や便利機能をプログラムで実装したセットがライブラリです。
目的ごとにいろいろなライブラリがあります。計算に使う NumPy やデータ解析に使う Pandas などが有名なライブラリです。
参考:【図解】Pythonのライブラリ 24選+α #Python – Qiita
URL:https://qiita.com/python_academia/items/62aefbf4e373cd2aa496
組み込み関数も標準ライブラリとして実装されているのでコードを書かなくても使えるようになっています。
標準ライブラリはコードを書かなくても使えますが、他のライブラリはインポートすることで使えるようになります。
import Pandas as pdインポートは Python のインタープリタにライブラリを読み込ませるための手続きです。
「as pd」は別名を付ける記述です。Python のライブラリはライブラリの名前をモジュール名として使う仕様です。文字数が多いと不便なので省略して使うことが慣例になっています。
Google Colaboratory には最初からいくつかのライブラリが入っていますが、入っていないものはインストールすることで使えるようになります。
ライブラリのインポート方法は Python のバージョンやライブラリによって異なることがあるので、使うときに調べてください。
Google Colaboratory を使う前提だったので説明してきませんでしたが、普通は最初にライブラリのインストールやインポートを行います。
クラスのインポート
ライブラリの中で使うクラスだけをインポートすることもできます。クラスが属している上位階層をfromで指定します。
#「selenium.common.exceptions.NoSuchElementException」をインポートする場合
from selenium.common.exceptions import NoSuchElementExceptionライブラリのインストール
標準ライブラリや Anaconda パッケージに入っているライブラリはすでにインストールされているので、何もせずにインポートして使うことができます。
それ以外の外部ライブラリを使う場合は、自分でインストールしないと使えるようになりません。インポートしようとすると警告やエラーが出るので、必要なものをインストールしてください。
行頭に「!」を付けるとコンソールと同じようにコマンドが使えるので Jupyter からインストールできます。
!pip install seleniumAnaconda Prompt や PowerShell などのコンソール(プロンプト/ターミナル)を使います。
pip install pandasライブラリがインストールされているか確認
インポートでエラーになったときなどに、そもそもインストールされているか確認します。
- pip show [Library Name] のバージョン確認コマンドで not found になれば存在しない
- pip list コマンドで一覧表示
エスケープシーケンス
他の言語とおおむね同じ仕様です。Pythonでは、それ以外に、f文字列やr(raw)列(文字列)の仕様が追加されています。(f文字列はVer.3.6で追加)
f文字列
初期化時に変数が使える文字列、{}内に変数を入れて表現する。
例)num=2のとき文字列f’Number={num1}’の内容はNumber=2として扱われる
r(raw)列
エスケープシーケンスを無視する文字列。
例)文字列「r’C:\win’」の内容は「C:\win」として扱われる。(通常は「\\」と書く必要がある)
Pythonでよく使う処理
待機(処理の終了待ちなど)
単に指定時間だけ処理を止めるsleep関数や、指定条件になるまで処理を待つWaitクラスなどがあります。
sleep(10)乱数生成(randomモジュール)
毎回異なる値や要素にしたいときに使います。
import random
# 0から1の範囲でランダムな浮動小数点数を返す
f_num = str( random.random() )
print('1:' + f_num)
# 引数1から引数2までの範囲でランダムな整数を返す
i_num = str( random.randint(1, 5) )
print('2:' + i_num)
# 引数1から引数2までランダムな浮動小数点数を返す
f_num = str( random.uniform(0, 1) )
print('3:' + f_num)
# シーケンスからランダムに1つの要素を返す
seq = ['one', 'two', 'three']
print( '4:' + random.choice(seq) )
# シーケンスの要素をランダムに入れ替える
seq2 = ['one', 'two', 'three']
random.shuffle(seq2)
print( '5:' + str(seq2) )乱数なので結果は毎回違います。注意してください。
--- output sample ---
1:0.09697865330714384
2:10
3:0.2559869403507312
4:one
5:['three', 'one', 'two']フォルダ作成
すでにフォルダがあるとエラーになるので無視する例です。
import os
try:
os.makedirs('FolderName')
except FileExistsError:
pass時間の取得と表示
ログや開始終了時間などを記録したいときに使います。
import time
current_time = time.strftime("%H:%M:%S")
print("current time:", current_time)命名規則とコーディングルール
ルールを守れば自他のコードに対する可読性が上がるメリットがあります。
個人開発なら関係なさそうですが、個人開発でも公式ドキュメントや他人の書いたコードを早く理解できるようになるので効率が良いです。
Pythonの基本が身に着いたら、次は命名規則とコーディングルールも知っておいた方がいいです。
まずは、変数名や関数名はスネークケース(小文字の単語をアンダーバーで連結)、クラス名はキャピタライズ(単語の先頭のみ大文字)、グローバル変数は先頭にダブルアンダーバーを付けるくらいは守っておきましょう。
他のルールは迷ったときに調べればいいでしょう。
そもそも、名前は自由に付けられるものの、プログラミングの世界では言語や分野ごとにおおむね守られているルールがあります。
Pythonの場合はPython以前の命名規則を受け継ぎつつ、独自の規則が公式に定められているので、これに従うべきです。
参考:[公式] Python コードのスタイルガイド pep8-ja 1.0 ドキュメント
URL:https://pep8-ja.readthedocs.io/ja/latest/
参考サイト
文法などの解説
参考: Python早見帳
URL:https://chokkan.github.io/python/index.html#
無料教材
参考:【2023年】プログラミング・Pythonの無料おすすめ学習教材13選 – Qiita
URL:https://qiita.com/skillup_ai/items/75e892e166f41ca85bf8
間違いやすいポイント
参考:Pythonの罠10選
URL:https://qiita.com/python_academia/items/c71fdd6c08c27a3cf2e0
Pythonでスクレイピング
Webサイトをクローリングしてデータを取得した後に、データを解析するスクレイピングのやり方を説明します。
ライブラリ
スクレイピングではRequestsとBeautifulSoupを使います。どちらもcondaパッケージに入っているのでインストール不要です。
- Requests:HTTP通信(外部ライブラリ)
- urllib:HTTP通信(Requestsと同等の機能を持つ標準ライブラリ、外部ライブラリをインストールできない環境ではこちらを使う)
- BeautifulSoup:Web情報の取得(HTMLなど)
デベロッパーツール(開発ツール)
Webページの解析に使うツールで Chrome や Firefox などのブラウザに組み込まれています。
F12キー右クリックから「検証/調査」などで起動できます。
スクレイピングでは左上の「ページから要素を選択」や「要素(インスペクター)」など使ってHTML要素を分析します。
欲しいデータを特定するためのタグやクラス名などを調べるのに使います。
参考:ブラウザの開発ツール(F12)を使いこなしたい!! – Qiita
URL:https://qiita.com/AumyF/items/5402c5b43391f5cbd1b2
Seleniumeのインストールと使い方
ブラウザの操作を自動化するツールで、Python から呼び出して使います。主にJavaScriptを使った動的に変化するページの解析に使います。
ボタンを押す必要があるログイン操作なども自動化できるので便利です。HTMLが動的に変化しないページの解析だけなら特に必要ありません。
ブラウザと Python のライブラリをインストールすると使えるようになります。
よくあるエラーと対処法
インストールやライブラリ/パスの設定後にコードを実行するとPermissionErrorなどが出ることがあります。
PermissionErrorは実行権限がないという意味ですが、本当の原因はパスやバージョンにある可能性があります。
先に原因を挙げておきますので、あせらずに次のことを確認してください。
- パスは合っているが肝心のファイル名を書き忘れている(/chromedriverまで書く)
- ソースコードで指定しているドライバのパスが間違っている
- ドライバをインストールした場所が違う(パスが違う)
- ドライバのバージョンが違う
- そもそもドライバがインストールされていない(ダウンロードやコピーができていない)
- 初期の記述方法が変わった影響 ⇒ SeleniumとChromeDriverManagerについて(備忘録)
以上のどの原因にも該当しない場合は、Pythonが出力するエラーに該当する可能性があるので、次はそちらに対処してください。
ドライバーインストール
シェアが多いChromeブラウザでのやり方を説明します。
まず、自分が使っているChromeのバージョンを調べて置き、次にダウンロードサイトから近いバージョンのものをダウンロードします。
Chromeのバージョンは点々のメニューから「Chrome について」を選べば確認できます。タブで開くのでそのままに確認できるようにしておきましょう。
参考:ダウンロードサイト ChromeDriver – WebDriver for Chrome – Downloads
URL:https://chromedriver.chromium.org/downloads
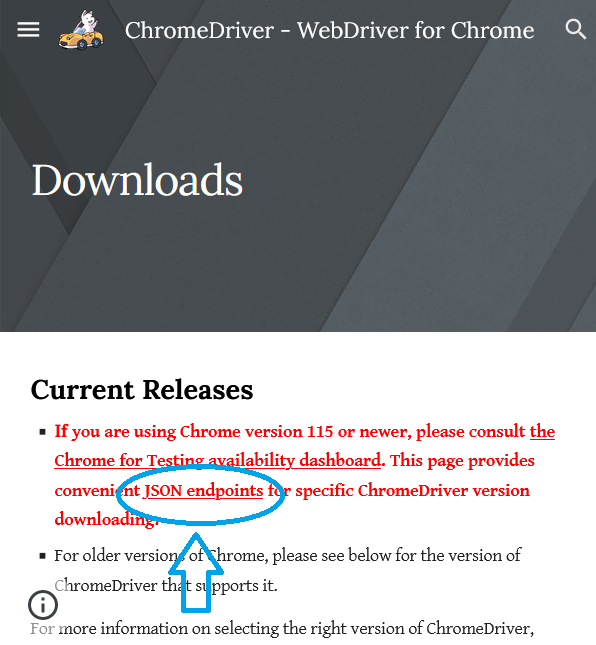
赤文字をよく見ると「JSON endpoints」がリンクになっているので ここから次のページに行きます。
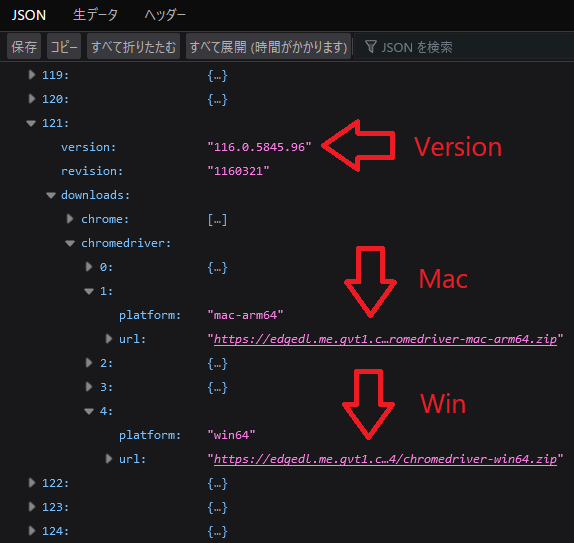
JSONファイルはツリー構造になっているので番号の△を開いて中身を確認します。
自分が使っているChromeと同じバージョンを探してOS別のchromedriver.zipをダウンロードします。
あとはzipファイルを解凍して、出来たファイルはカレントフォルダ(※)や自分のライブラリフォルダに移動すれば、インストール完了です。
ドライバのバージョンは自分で管理しないといけません。
バージョン情報をフォルダ名につけたり、Pythonコードにメモしたりしておくのがおすすめです。
(※:プログラムを実行する作業フォルダのこと、Jupyter Notebookなら最初に設定したルートフォルダーのこと、分からないときはJupyter Notebookで作ったPythonファイル名をファイル検索するなどして調べる)

ちなみに前のページのJSONリンクの上にあるリンクからはテスト用のChromeをダウンロードすることもできます。
普段のブラウジングに使うChromeは頻繁にバージョンアップされるので、別に用意しておくとドライバーの変更が不要になって便利です。
Chromeの自動アップデートを停止
Chromeブラウザは何もしないと自動で最新バージョン更新され、ドライバーが使えなくなるのでSeleniumなどが動かなくなります。
いざというときに使えなくなると不便なので自動アップデートを停止しておくことをおすすめします。
Windowsでの簡単な停止方法は「GoogleUpdate.exe」をリネームしてしまうことです。
ファイル検索はEverythingが高速で便利
リネームした名前はどこかに記録しておかないと分からなくなるので注意してください。
この方法ではエラーが出るようになるので気になる人は別のやり方で停止させてください。
ライブラリのインストール
Anaconda NavigatorからPythonにseleniumのライブラリをインストールします。
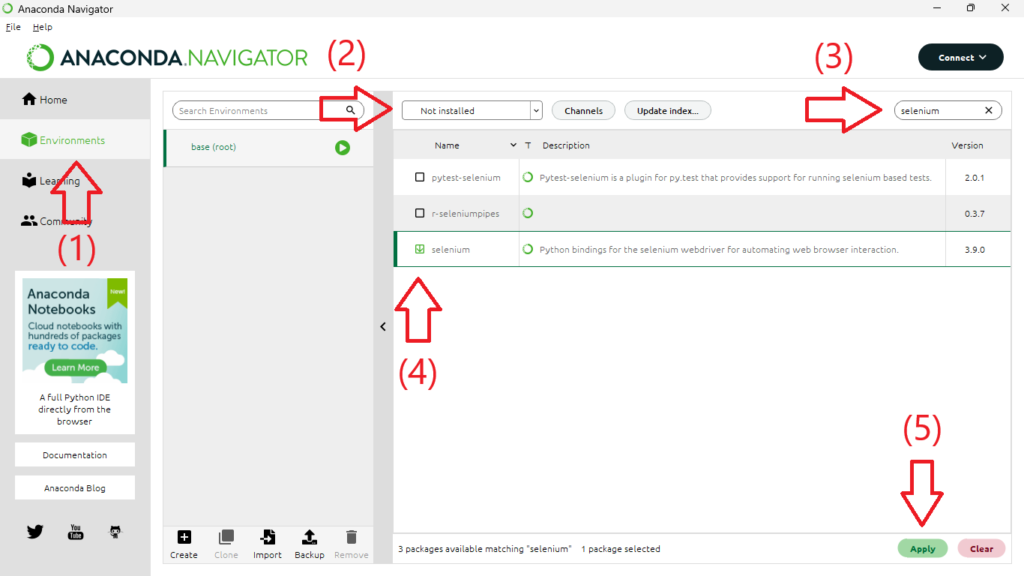
- 「Environments」を選択
- 「Not Installed」を選択
- 「selenium」と入力して検索
- 「selenium」をチェック
- 「Apply」を選択
以上の手順で準備完了です。
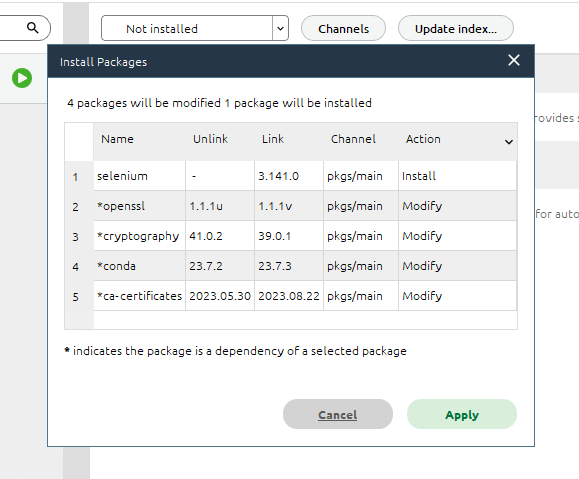
しばらくすると上のインストール予定ウィンドウが出るので「Apply」を選択すればライブラリのインストールが開始されます。
完了するとウィンドウが消えるので、二つ上の画像の(2)で「Installed」を選んで「selenium」と表示されていればライブラリのインストールは成功です。
Seleniumの使い方
ブラウザを起動してデータを取得し、ファイルに書き込む流れのサンプルです。
複数ページから取得するときは、あらかじめURLリストを作っておくか、次のページのURLなどを取得して、処理を繰り返します。
このサンプルはテキストファイルに書き込んでいますが、スクレイピングではDataFrameを使いCSVファイルに書き込むことのほうが多いです。
# 使用ライブラリ
from selenium import webdriver
# ドライバーの起動
# Win
driver = webdriver.Chrome(r'C:\[インストールフォルダのパス]\python\lib\selenium\chromedriver-win64_ver_116_0_5845_96\chromedriver.exe')
# Mac
#browser = webdriver.Chrome()
# ヘッドレスモード(ブラウザ非表示)で起動
from selenium.webdriver.chrome.options import Options
# Chromeオプションを設定する
chrome_options = Options()
chrome_options.add_argument('--headless')
# WebDriverを起動する
driver = webdriver.Chrome('同上のインストールフォルダのパス', options=chrome_options)
# ページデータ取得
url = 'https://target-page-sample.com'
driver.get(url)
# クラス名から必要な要素を取得
page_text = driver.find_element_by_class_name('CLASS-NAME').text
# テキストファイルに書き込む(aは追加書き込み)
with open('TEXT-FILE-NAME.txt', 'a', encoding='utf-8') as f:
f.writelines(page_text)
# タグの要素を取得
a_tag = driver.find_element_by_class_name('NEXT-PAGE')
next_page_url = a_tag.get_attribute('href')
# ブラウザを閉じる(終了)
driver.quit()スクレイピング可能サイトか確認
利用規約でスクレイピングを禁止しいているサイトがあります。
スクレイピングを始める前にそのサイトの規約を確認してスクレイピング可能か判断しないといけません。
悪意はなくても結果的にサイトのサーバーに過剰な負荷をかけなどすると運営妨害行為と判断され罰せられる恐れがあります。
規約で禁止されていなくても、相手サイトに迷惑がかからないようにしないといけません。
具体的にはアクセス間隔をあけたり、相手サーバーのトラフィックが少ない深夜帯にアクセスするなどの方法があります。
スクレイピング禁止サイトと判断方法
- X(Twitter)
- メルカリ
- Amazon
以上のサイトへのスクレイピング案件がクラウドソーシングに出ていることがあります。
ですが、自分がスクレイピングツールを使わなくても、作るだけで幇助罪という手助けした罪になる恐れがあるので関わらないほうがいいです。
- スクレイピング(scraping)
- クローリング(crawling)
- 自動(操作)、自動化(aute)
- ロボット(robot)
以上のような言葉でスクレイピングが禁止であることを表すので、これらを検索して前後の内容を確認してください。
英語サイトはカッコ内の英単語で検索して翻訳しましょう。
robtos.txtで詳しく調べる
各サイトはルートに「robots.txt」というテキストファイルを設置していて、これにクローラーに対する指示が書かれています。
アクセス禁止フォルダなどが書いてあるので、これに従えば違反なくクローリングすることができます。
ルートにあるので[トップページのURL+/robots.txt]でアクセスすれば内容を確認できます。
robots.txt内の*(アスタリスク)は正規表現などで使うすべてを表す記号です。
Disallowがアクセスを許可しないという意味で、その右の「: /bin」などが対象ディレクトリ(フォルダ)を表しています。
Allowがアクセスを許可するという意味です。Disallow以外はアクセスしてよいので、Allowは省略されていることも多いです。
BeautifulSoupでダメなときはやSeleniumやXmlパーサ
静的なHTMLならBeautifulSoupだけでデータが取得できますが、JavaScriptで後から更新されるような動的なデータを取得するにはSeleniumを使う必要があります。
BeautifulSoupは一部の複雑なHTMLなどは正しく解析できません。そんなときはXmlパーサを使えば取得できます。
Seleniumを使う方法
HTML のタグやクラスが取得できないときは Seleniumu の webdriver を使うと取得できることがあります。
Selenium なら動的に変更された後のHTMLデータを取得できるからです。表示に時間がかかるときは、表示されるまで待つ処理を使いましょう。
これは BeautifulSoup で取得できるオリジナル HTML に日時が含まれておらず、後から動的に HTML の内容を更新するシステムなど起こります。
時差を考慮して日時を現地時間で表示するグローバル対応をするときなどに、JavaScriptなどで後から動的に HTML を変更するため、そのような実装になります。
それでも取得できないときは、サーバーがスクレイピングやクローリングを拒否している可能性があるので他の方法を探しましょう。
htmlデータさえ取得できれば、同じようにBeautifulSoupで解析できます。
Xmlパーサを使う方法
import os
from lxml import html
# データ取得
file_path = os.path.join(folder_path, file_names)
with open(file_path, 'r', encoding='utf-8') as f:
html_data = f.read()
# 解析
parsed_html = html.fromstring(html_data)
# divタグのentry_bodyクラスのデータを取得
body_date = parsed_html.xpath('//div[@class="entry_body"]')正しい構文のHTMLデータさえ取得できていれば、Xmlパーサで確実にデータを解析することができます。
データの特定に正規表現を使う必要が出てくることもありますが、今はAIに聞けば正確な正規表現が分かるので、特に難しいことはありません。
初めからXmlパーサで処理を組んでおけば、BeautifulSoupを使うリスクをさけられます。
BeautifulSoupだとデータ取得できないときにエラーとかが出なくて、原因が分かりにくい。
だから、仕事で堅牢なプログラムを組みたいならXmlパーサを使っておいたほうがいいね。
趣味のスクレイピングならBeautifulSoupのほうが楽でいいけど。
スクレイピングでよく使う処理
サンプルコードのメモです。文字列を操作するときは別項の「文字列の処理(str型)」を参照してください。
- Pandas(pd): データ分析用ライブラリ
- Requests:http通信用ライブラリ
- selenium:ブラウザ自動化ライブラリ
- soup:BeautifulSoup4のインスタンス
- webdriver:seleniumのブラウザ自動操作用クラス
名前を間違いやすいので注意
html要素の名前が間違っていても、エディターが教えてくれないので、間違いに気付きにくいです。そこで素直にコピペしてくると、今度はスペースが入っていて意図した結果にならいことがあります。
htmlデータの取得
HTMLデータを取得し、BeautifulSoupで解析するサンプルです。複雑なHTMLを解析するときに役立ちます。
BeautifulSoupは、まずfind_allで内容を確認してから、findなどで要素を限定していくと解析しやすいです。
データが取得できなかった場合の対処法は次の項目を参照してください。
# ライブラリのインポート
import requests
from bs4 import BeautifulSoup
# htmlの取得
res = requests.get(’https://www.website-sample.com’)
# 文字化け対策 見た目とエンコーディングを合わせる設定
res.encoding = res.apparent_encoding
# 解析
soup = BeautifulSoup(res.text, 'html.parser')
# htmlデータの取得
html_data = [] # この記述は不用だがリストデータであることを明示するため書いている
html_data = soup.find_all()
# htmlをインデント付で表示
print(soup.prettify())
# 特定タグを指定してデータ取得(最初の一つを取得)
p_tag = soup.find('p')
# 特定タグのインスタンス変数からデータ取得(上記と同じ結果になる)
p_tag = soup.p
# タグの中身だけを取得(タグを除いたデータ)
p_tag = soup.p.text
# タグの要素を取得:イメージタグのsrcを取得する例
img_tag = soup.find('img')
src = img_tag['src']
src = soup.find('img')['src'] # 上の2行を1行にまとめた処理
# クラス(html要素)を指定して取得(配列データなのでインデックスを指定する)
class_tag = soup.find_all('p', attrs={'class':'sample-class-name'})[0]
# CSSセレクタを指定したデータ取得(「.」+クラス名など)
tag_date = soup.select('.class-name') #リストで取得
tag_date = soup.select_one('.class-name') #ひとつだけ取得
tag_date = soup.select_one('.class-name').text #タグの内容だけ取得タグデータの削除
一度削除すると元に戻せません(Jupterのキャッシュからも消える)。復活させるにはhtmlデータから再取得します。
# 該当タグ内のspanタグの削除
tag_no_span = tag.find('span', attrs={'class': 'class-name'}).extract()
# 正規表現で数字を削除
import re
text = "Number delete 123 and [45]"
res = re.sub(r"\d+", "", text)
print(res)
--- output ---
Number delete and []HTML/CSS/JavaScriptの理解が必須
スクレイピングするのはHTMLデータなので解析するための最低限の知識は必要になります。HTMLの装飾で使われるCSSや動的な機能を提供するJavaScriptについても同様です。
とはいえ、HTMLは基本的にはXMLのような入れ子状のマークアップ言語なので、タグや要素が分かればおおむね理解できます。
CSSはデザイン用のクラスのようなものですが、CSSセレクタなど独特な部分もあるので理解しておくべきです。
JavaScriptはブラウザ上で動的に動く機能で、HTMLファイルやJSファイルなどに記述されたプログラミングコードになっています。
名前にJavaとついているだけあってJava言語との共通点は多いですが、基本的には別物なので、どういうものか理解しておくべきです。
ページ内でのタブ切り替えや、リスト表示など変化する動的な処理を行うことができます。
HTMLの解析はデベロッパーツール
ChromeやFirefoxなどのWebブラウザにはデベロッパー(開発/検証)ツールがビルドインされていて、ショートカットキーで呼び出すことができます。
HTML要素だけでなくJavaScriptの動きなども確認できるWeb開発に必須のツールになっています。
- Windows: Ctrl + Shift + I または F12
- Mac: Command + Option + I
文字列の処理(str型)
# 置換や不要な文字列の削除
s = s.replace('Average', 'Avg.') # 引数1を引数2に置換
s = s.replace('\n', '') # 指定文字の削除
# 区切り記号を指定して複数の文字列に分割、数字だけ整数型にして取り出す
title='TITLE:123'
print( int( title.split(':')[1] ) )
# 複数行に連続する改行を1つに置換(省略)
import re
text = re.sub("\n+", '\n', text)ファイル操作
テキストファイルの操作
# ファイルの読み込み
with open('sample.txt', 'r') as f:
text = f.read()
# 複数行のテキストデータ(リスト[エンティティ])のファイルへの書き込み
# 日本語がエンコードエラーにならないように utf-8 を指定
# open関数の第二引数は、w:新規作成, a:追記
with open('sample.txt', 'w', encoding='utf-8') as f:
f.writelines(text)DataFrame:CSVへの書き込みなど
CSVファイルなどの操作はPandasライブラリで行えます。
DataFrameはPandasライブラリのクラスで、内部にindex/columns/values(NumPy配列)を持っています。
import pandas as pd
# 辞書データを元にデータファイルを作成する例
df = pd.DataFrame(data)
# 簡単なカラムの入れ替え例:カラム名を指定するとその順番に変わる
df = df[['cn2', 'cn3', 'cn1']]
# CSVファイルへの出力(ファイル作成)例:自動で付与されるindexカラムが不要な場合の例
df.to_csv('file_name.csv', index=False)
# 行列データの数の確認:行・列の順で数を確認できる
print(df.shape)
# DataFrameの指定した行列や複数指定
print( df.loc[1, 'c1'] ) # c1カラムのインデックス2番目のデータ
print(df.loc[[1, 4'], ['c1', 'c3']]) # c1からc3カラムの2番目と5番目のデータ
# 行列の抽出:範囲リストを作って指定
l_c = ['col_1', 'col_3']
df[l_c]
# リスト内容を直接記述するのはエラー
# df['col_1', 'col_3']

コメント